PyTorch学习 1:张量Tensor、计算图、前向传播、反向传播、梯度计算与更新 Tensor基础概念 张量(Tensor)是一个多维数组,可以是标量(零阶张量)、向量(一阶张量)、矩阵(二阶张量)或更高维度的数据结构(N阶张量)。
Tensor底层模型 Tensor的底层模型或结构主要可以从数据存储机制 和计算引擎结构 两个方面来理解。
1、底层存储模型:元数据与Storage存储区 Tensor的底层由两部分组成:
元数据区(Metadata/View) :描述Tensor的信息,包括形状(size/shape)、步长(stride)、数据类型(dtype)、设备(CPU/GPU)、存储偏移量(storage_offset)等。
存储区(Storage) :实际存放Tensor数据的区域,通常是一个线性的一维数据。不同的Tensor(如经过view、transpose操作)可以共享同一个Storage。
在pytorch中可使用tensor.storage()访问存储的数据
1 2 3 4 5 6 7 8 9 >>> import torch>>> data = torch.arange(9 )>>> print (data.storage().dtype)<stdin>:1 : UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class . torch.int64 >>> print (data.storage().device)cpu >>> print (data.storage().data_ptr())2823601262912
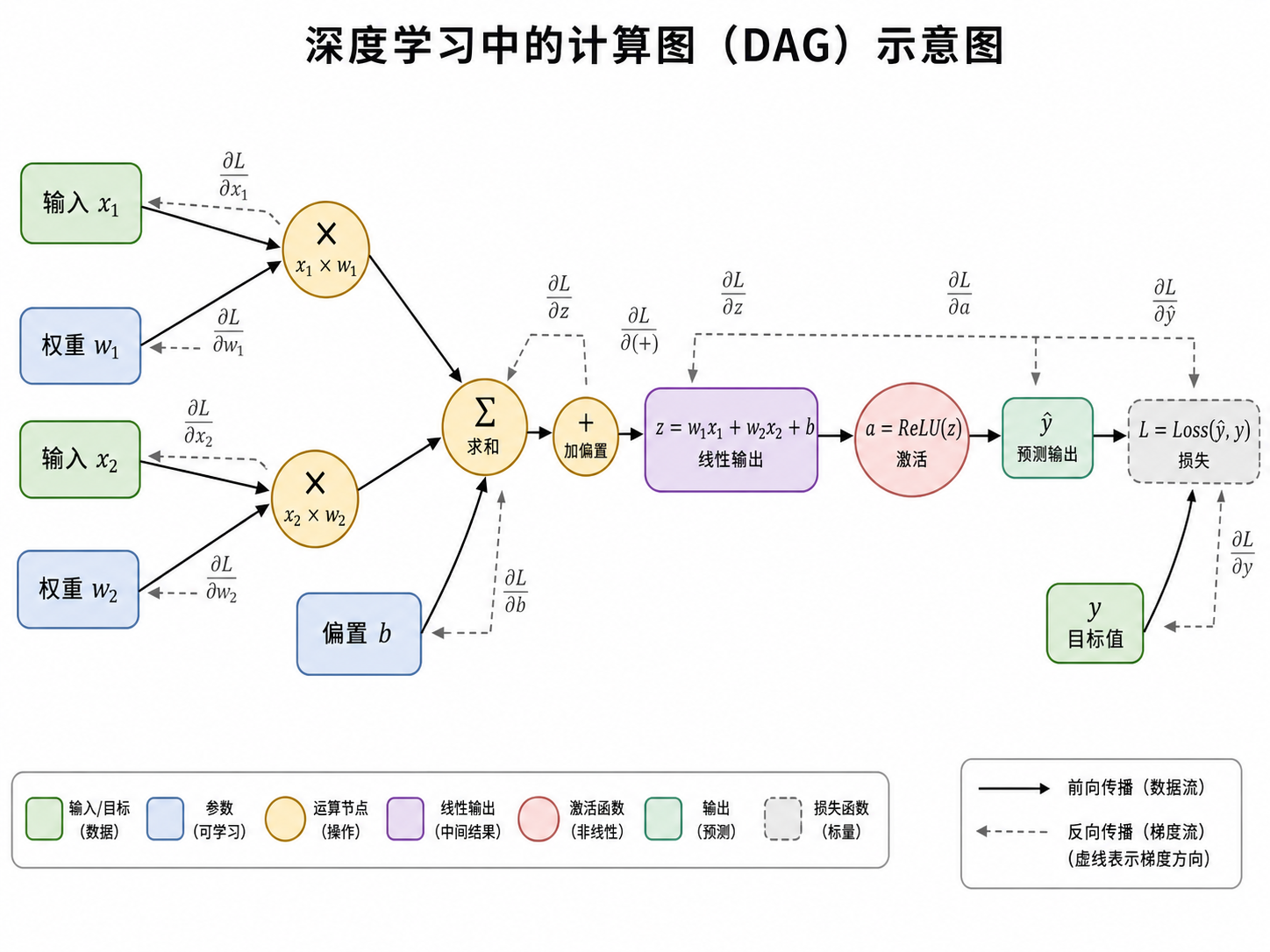
2、底层数据结构:DAG计算图 Tensor不仅是数据,还是深度学习计算图(Directed Acyclic Graph,DAG,也叫有向无环图)中的节点。
节点(Node):每个Tensor对应计算图中的一个节点
操作(Operator):矩阵乘法、加法等运算对应图中的操作节点。
反向传播:框架依据DAG记录的运算历史,从损失(loss)出发,反向遍历计算梯度(Backward)。
图中的模型是一个 单个神经元/线性层+ReLU激活+损失函数的计算图,是深度学习中最基本的前向传播和反向传播DAG。
\[z=w_1x_1+w_2x_2+b\]
然后经过激活函数:
\[a={ReLU}(z)\]
把激活后的结果作为预测值:
\[\hat{y}=a\]
最后和真实目标值\(y\) 计算损失:
\[L=Loss(\hat{y}, y)\]
所以图中描述的是:输入\(x_1,x_2\) 经过权重\(w_1,w_2\) 和偏置项\(b\) 得到预测值\(\hat{y}\) ,再与真实值\(y\) 比较,得到损失\(L\) 。
3、前向传播 图中的实线箭头 表示前向传播,也就是数据流。
\[m_1=x_1w_1\\
m_2=x_2w_2\]
这里\(m_1\) 和\(m_2\) 是中间计算结果。
\[s=m_1+m_2\]
第三步,加上偏置:
\[z=s+b\]
也就是:
\[z=w_1x_1+w_2x_2+b\]
第四步,通过\(ReLU\) 激活函数:
\[a=ReLU(z)=max(0,z)\]
也就是:
如果\(z>0\) ,那么\(a=z\)
如果\(z\le0\) ,那么\(a=0\)
第五步,得到预测输出:
\[\hat{y}=a\]
第六步,和真实值\(y\) 计算损失:
\[L=Loss(\hat{y},y)\]
如果用均方误差举例:
\[L=\frac{(\hat{y}-y)^2}{2}\]
4、反向传播 图中的虚线剪头 表示梯度流,即反向传播,也就是从损失\(L\) 开始,计算每个参数对损失的影响。
\[w_1,w_2,b\]
所以需要算:
\[\frac{\partial L}{\partial w_1}, \quad \frac{\partial L}{\partial w_2}, \quad \frac{\partial L}{\partial b}\]
这些梯度表示:如果稍微改变某个参数,损失\(L\) 会怎样变化。
5、梯度如何通过图传播 反向传播的核心是链式法则 。
\[\frac{\partial L}{\partial \hat{y}} = \hat{y} - y\]
由于:
\[\hat{y}=a\]
所以:
\[\frac{\partial L}{\partial a}=\frac{\partial L}{\partial \hat{y}}\]
又因为:
\[a=ReLU(z)\]
所以:
\[\frac{\partial a}{\partial z} =
\begin{cases}
1, & z > 0 \\
0, & z \le 0
\end{cases}\]
因此:
\[\frac{\partial L}{\partial z} = \frac{\partial L}{\partial a} \cdot \frac{\partial a}{\partial z}\]
这一步非常关键,因为\(ReLU\) 可能会把梯度截断。
6、参数梯度的计算 因为:
\[z=w_1x_1+w_2x_2+b\]
所以:
\[\begin{align*}
\frac{\partial z}{\partial w_1} &= x_1 \\
\frac{\partial z}{\partial w_2} &= x_2 \\
\frac{\partial z}{\partial b} &= 1
\end{align*}\]
根据链式法则:
\[\begin{alignat*}{2}
\frac{\partial L}{\partial w_1} &= \frac{\partial L}{\partial z} \cdot \frac{\partial z}{\partial w_1} &&= \frac{\partial L}{\partial z} \cdot x_1 \\
\frac{\partial L}{\partial w_2} &= \frac{\partial L}{\partial z} \cdot \frac{\partial z}{\partial w_2} &&= \frac{\partial L}{\partial z} \cdot x_2 \\
\frac{\partial L}{\partial b} &= \frac{\partial L}{\partial z} \cdot 1 &&= \frac{\partial L}{\partial z}
\end{alignat*}\]
这就是神经网络中参数更新的基础。
7、具体数值示例 假设:
\[x_1=2,x_2=3\\
w_1=0.5,w_2=-1,b=1\]
真实值:
\[y=1\]
前向传播 先算乘法节点:
\[\begin{align*}
m_1 &= x_1 w_1 = 2 \times 0.5 = 1 \\
m_2 &= x_2 w_2 = 3 \times (-1) = -3
\end{align*}\]
求和:
\[s=m_1+m_2=1+(-3)=-2\]
加偏置:
\[z=s+b=-2+1=-1\]
经过\(ReLU\) :
\[a=ReLU(-1)=0\]
所以预测值:
\[\hat{y}=0\]
如果损失函数是:
\[L=\frac{(\hat{y}-y)^2}{2}\]
那么:
\[L=\frac{1}{2}(0-1)^2=0.5\]
反向传播 上面例子中,
\[z=-1\]
所以:
\[a=ReLU(z)=0\]
并且:
\[\frac{\partial a}{\partial z}=0\]
因此:
\[\frac{\partial L}{\partial z}=0\]
进一步得到:
\[\begin{align*}
\frac{\partial L}{\partial w_1} &= 0 \\
\frac{\partial L}{\partial w_2} &= 0 \\
\frac{\partial L}{\partial b} &= 0
\end{align*}\]
这说明在这个具体数值下,\(ReLU\) 处于关闭状态,梯度传不过去,参数暂时无法通过这个样本更新。这也是\(ReLU\) 的一个典型特征。
换一个\(z>0\) 的例子 假设:
\[x_1=2,x_2=3\\
w_1=1,w_2=1,b=0\]
真实值:
\[y=10\]
前向传播:
\[\begin{gather*}
z = 1 \times 2 + 1 \times 3 + 0 = 5 \\
a = \text{ReLU}(5) = 5 \\
\hat{y} = 5
\end{gather*}\]
损失:
\[L=\frac{1}{2}(5-10)^2=12.5\]
反向传播:
\[\frac{\partial L}{\partial \hat{y}} = \hat{y} - y = 5 - 10 = -5\]
因为\(\hat{y}=a\) ,所以:
\[\frac{\partial L}{\partial a}=-5\]
因为\(z=5>0\) ,所以:
\[\frac{\partial a}{\partial z}=1\]
因此:
\[\frac{\partial L}{\partial z}=-5\]
参数梯度:
\[\begin{align*}
\frac{\partial L}{\partial w_1} &= -5 \times x_1 = -5 \times 2 = -10 \\
\frac{\partial L}{\partial w_2} &= -5 \times x_2 = -5 \times 3 = -15 \\
\frac{\partial L}{\partial b} &= -5
\end{align*}\]
如果用学习率\(\eta = 0.1\) ,梯度下降更新为:
\[\begin{align*}
w_1 &\leftarrow w_1 - \eta \frac{\partial L}{\partial w_1} \\
w_1 &\leftarrow 1 - 0.1(-10) = 2 \\
w_2 &\leftarrow 1 - 0.1(-15) = 2.5 \\
b &\leftarrow 0 - 0.1(-5) = 0.5
\end{align*}\]
因为预测值5小于真实值10,所以梯度更新会让参数变大,从而提高之后的预测值。